


The success of deep learning in natural language processing (NLP) rendered language-specific feature design rare but saw cross-lingual transfer methods flourish. NLP is a branch of artificial intelligence that helps computers understand, interpret, and manipulate human language. It is estimated that Africa has more than 2000 living languages but most of these languages have very little data. This makes it difficult to develop speech and language technologies that are relevant to the African context. For this reason, these languages are referred to as “low-resource languages”. In this post we discuss the following aspects of this research:
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has to date not been sufficiently solved. It is a complex problem that goes beyond data availability and reflects systemic problems in society. The research paper this summary is based on was a collaborative effort by a large number of authors from across Africa. It describes how a participatory approach has enabled them to set machine translation benchmarks for 30 African languages which will allow researchers to make further improvements. Dr Herman Kamper, a senior lecturer in the Department of Electric and Electronic Engineering, and Elan van Biljon, an MSc student in Computer Science formed part of this collaboration. This means that, for the first time, machine translation systems have been developed to translate these different African languages to English and vice versa in the same way Google Translate would translate other mainstream languages. The research paper ultimately won the inaugural Wikimedia Foundation Research Award for 2020.
1. The machine translation process
The machine translation process includes two sub-processes namely a dataset creation process and a model creation process. Content creators, translators, and curators form part of the dataset creation process, while the language technologists and evaluators are part of the model creation process. Stakeholders create demand for both processes. This enables a sustainable process for machine translation research on parallel corpora. The overall process is visualised below:
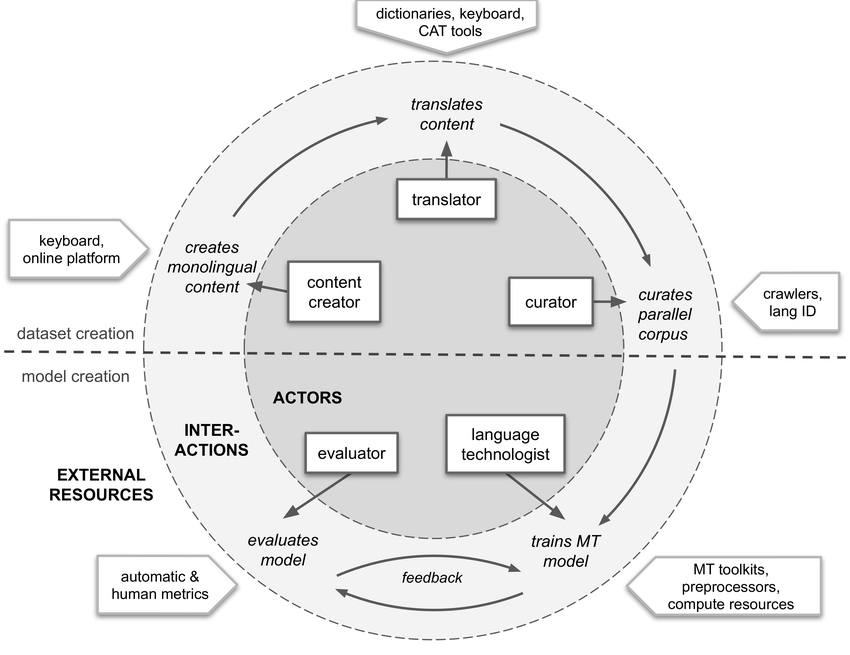
2. The Masakhane case study
African languages represent only a small fraction of available language resources, and NLP research seldom considers African languages. The Masakhane project is a grassroots initiative involving a virtual community of content creators, translators, curators, language technologists, and evaluators. Its mission is to address the lack of geographic diversity in the field and “to strengthen and spur NLP research in African languages, for Africans, by Africans”. It was established in 2019 by machine learning engineer Jade Abbott during the Deep Learning Indaba held in Kenya.
3. Use cases
Some of the use cases that resulted from this research include, amongst others, the following:
- Volunteers in Nigeria are currently translating their own writings, including personal religious stories and undergraduate research, into Yoruba and Igbo. This is to ensure that representative data of their culture is available and can be used to train models.
- In Namibia, Jade Abbot is hosting collaborative sessions with Damara speakers, to collect and translate phrases in Khoekhoegowab that reflect Damara culture around traditional clothing, songs, and prayers.
- In 2020 eleven participants volunteered to assess translations in their mother tongue, often involving family or friends to determine the most correct translations. In approximately 10 days, they collected a total of 707 evaluated translations covering Igo, Nigerian Pidgin, Shona, Luo, Hausa, Kiswahili, Yoruba, Fon and Dendi. This was the first time that human evaluation of an MT system has been performed.
4. Conclusion
The first efforts in building an automatic speech recognition system for Somali was presented as part of a United Nations programme aimed at humanitarian monitoring. Optimal performance was achieved by a multilingually-trained convolutional neural network – time delay neural network – bidirectional long short-term memory neural network (CNN-TDNN-BLSTM) acoustic model, achieving a word error rate of 53.75%. Augmenting the language model training data using a generative LSTM afforded small gains. The research also found that BLSTM layers consistently benefited more from subsequent adaptation to the target language than LSTM layers.
The final version of the paper this article is based on, has been published at:
Menon R, Biswas A, Saeb A, Quinn J, Niesler T. 2018. Automatic Speech Recognition for Humanitarian Applications in Somali. Available at http://arxiv.org/abs/1807.08669.