

Imagine driving in a new city with a sat-nav that slowly drifts off-course. Every few blocks, you’d need a landmark, say, the town hall, to reset your position. Robots have the same problem.
In visual simultaneous localisation and mapping (SLAM), the robot builds a map while estimating where it is. Each time it revisits a spot, it can “close the loop”, scrub away accumulated error, and keep its map honest. The catch? Accurate loop closure starts with recognising that the scene in front of the camera is the same one seen earlier.
Most loop-closure systems treat a scene as a cloud of geometric dots. They match corners, edges, or depth points but ignore what the dots mean: a car, a sign, a tree. Humans, by contrast, lean heavily on semantics—the objects themselves and how they relate. March Brian Strauss’s thesis, completed under supervision of Dr Corne Van Daalen, asks: could weaving those semantics into the maths give robots the same advantage?
The SeM2DP Idea in One Sentence
Combine a sparse 3D point cloud from a stereo camera with the pixel-level object labels from a neural-network segmenter, then compress the blend into a compact 256-number “fingerprint” called Semantic Multiview 2-D Projection (SeM2DP).
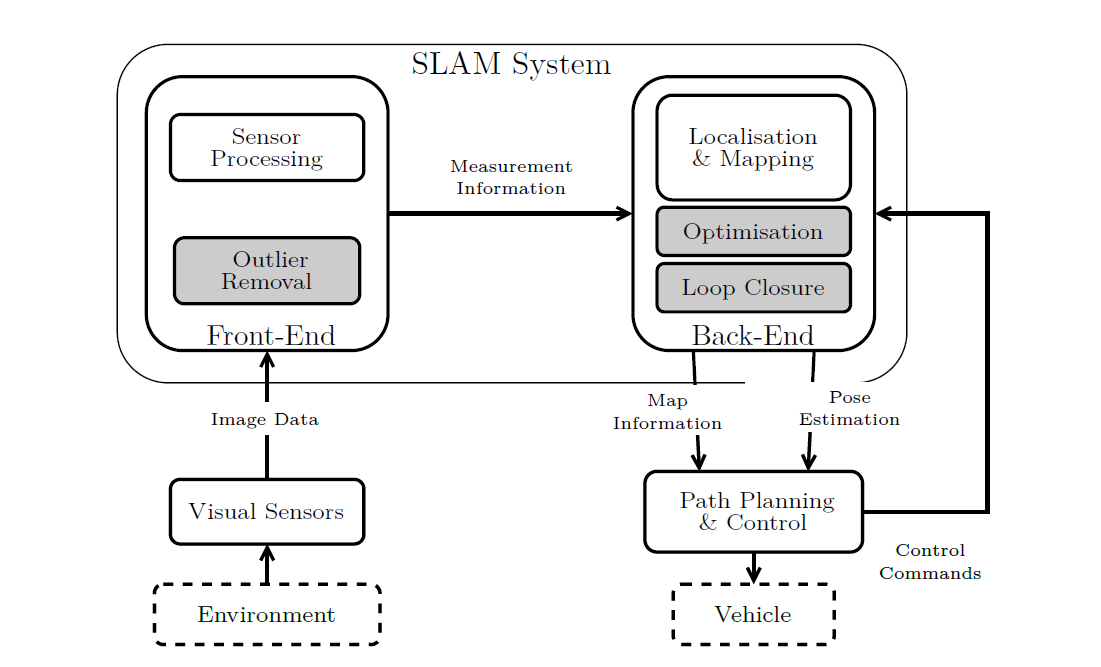
Figure 1: A block diagram of a generic, vision-based SLAM system.
How it Works (Without Equations)
- See the world in 3D. Two side-by-side cameras capture a stereo pair. Classic feature detectors (SIFT works best here) locate distinctive pixels, match them across the pair, and triangulate their 3D positions.
- Label the pixels. A pre-trained MobileNetV2 network quickly colours every pixel with a class—road, car, building, sky, and so on.
- Fuse geometry and meaning. Each 3D landmark inherits the label of the pixel from which it originated. The result is a “semantic point cloud”: dots plus context.
- Project and bin. SeM2DP slices that cloud into several virtual camera views, turns each view into histograms that capture both where points fall and which labels dominate, and finally stitches everything into a single 256-float vector.
- Match fast. New vectors are compared using a k-nearest neighbour search. A close match flags “I’ve been here before”, triggering loop closure.
Because the fingerprint is short, storage and comparison remain lightweight even when the robot stores thousands of places.
Does it Actually Help?
Strauss ran SeM2DP on five standard KITTI stereo-odometry sequences and pitted it against two respected descriptors:
| Descriptor | Avg. mean-average-precision (mAP) | Vector length (floats) |
| SeM2DP | 0.81 | 256 |
| Colour-M2DP | 0.78 | 576 |
| Original M2DP | 0.50 | 192 |
Key takeaways:
- Higher accuracy. SeM2DP beat the colour-only variant in 3 of 5 sequences and trounced the geometry-only original everywhere.
- Half the storage. It matches the colour of M2DP while using less than half the descriptor length.
- Slower per frame. Full processing, including heavy semantic segmentation, takes roughly twice as long as the rivals (about 0.5 s per stereo pair on CPU). Dedicated GPU hardware or batching could shrink that gap.
Why the Slowdown is Worth It (Sometimes)
If your robot already runs neural networks for object avoidance, the segmentation step is “free”—SeM2DP simply re-uses those labels. In that context, you get a stronger, more weather- and viewpoint-tolerant place signature at negligible extra cost. Straus notes that the trend in robotics is toward richer scene understanding, so piggybacking on that computation makes practical sense.
That said, a few aspects still need work:
- Speed. Porting from Python to C++ and processing the left- and right-image segmentation in parallel could halve run-time.
- Full SLAM integration. The thesis proves loop-closure detection; testing inside a complete SLAM stack is next.
- Highly dynamic scenes. More study is needed when many objects move simultaneously
Bottom Line
Strauss shows that giving a robot context—not just shapes—makes it far better at realising, “I’m back at the lobby,” or “This alley looks familiar.” SeM2DP mixes 3-D geometry with object labels to create a compact fingerprint that’s more accurate than older methods and small enough for real robots to carry around. It runs slower today, but the payoff is cleaner maps, fewer navigation hiccups, and a step toward machines that see spaces a little more like we do.
Download and read the full research paper here: https://scholar.sun.ac.za/items/ffb2f4e6-7a82-4b12-8395-8b408099708d