


In May 1997, IBM’s Deep Blue became the first computer chess engine to defeat a reigning world champion in a chess game under regular time controls. This marked a historic moment for the field of artificial intelligence (AI). Deep Blue had no learning capabilities, and its chess-playing ability was entirely based on manually encoded expert knowledge combined with brute force search over possible future board positions. In that same year, a new competition was launched to become the next grand challenge for AI. This competition was named the Robot Soccer World Cup, or RoboCup for short.
In his recent PhD dissertation, Dr Andries Smit, under the supervision of Professor Herman Engelbrecht of the Department of Electrical and Electronic Engineering, investigated whether agents can learn competent soccer strategies in a full 22-player soccer game using limited computational resources (one CPU and one GPU), from tabula rasa and entirely through self-play.

Background
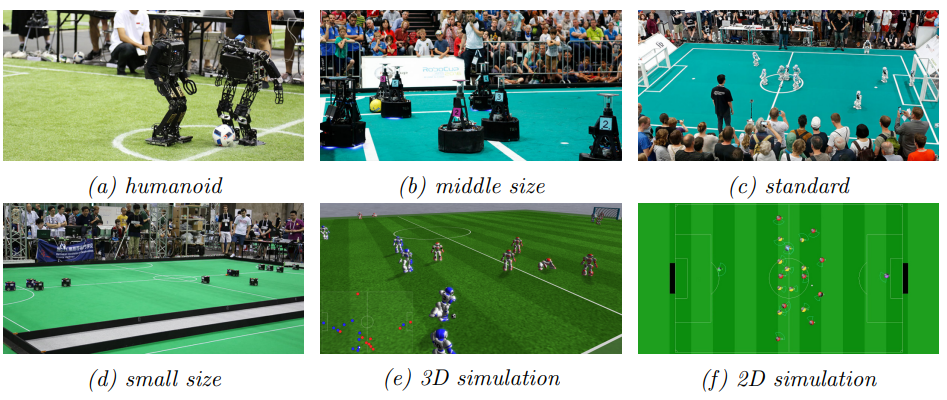
Robot soccer, where teams of autonomous agents compete against each other, has long been regarded as a grand challenge in AI. Despite recent successes of learned policies over heuristics and handcrafted rules in other domains, current teams in the RoboCup soccer simulation leagues still rely on handcrafted strategies and apply reinforcement learning only on small subcomponents.
This limits a learning agent’s ability to find strong, high-level strategies for the game in its entirety. End-to-end reinforcement learning has successfully been applied in soccer simulations with up to 4 players. The research discussed here had as its objectives to:
- investigate methods with which an efficient end-to-end MARL system, trained entirely through self-play, can scale to the full 22-player 2D soccer environment;
- design a custom 2D soccer environment with a faster runtime than the official 2D RoboCup simulator, for faster experimentation that remains sufficiently close to the RoboCup simulator with regards to the MARL-specific challenges it presents; and
- experimentally verify whether our solution can learn competent strategies through self-play by evaluating the trained teams against opponents with handcrafted strategies.
Methodology
To enable this investigation, Dr Smit built a simplified 2D soccer simulator with significantly faster simulation times than the official RoboCup simulator, which still contained the important challenges for multi-agent learning in the context of robot soccer. He proposed various improvements to the standard single-agent proximal policy optimisation algorithm in an effort to scale it to its multi-agent setting.
These improvements included:
- using a policy and critic network with an attention mechanism that scales linearly in the number of agents;
- sharing networks between agents, which allow for faster throughput using batching; and
- using Polyak averaged opponents with freezing of the opponent team when necessary and league opponents.
Results
Through experimental results, Dr Smit’s research showed that stable training in the full 22-player setting is possible. Agents trained in the 22-player setting learn to defeat a variety of handcrafted strategies and also achieve a higher win rate compared to agents trained in the 4-player setting and evaluated in the full 22-player setting.
He also evaluated our final algorithm in the RoboCup simulator and observed steady improvement in the team’s performance over the course of training. Dr Smit is optimistic that this work can guide future end-to-end multi-agent reinforcement learning teams to compete against the best handcrafted strategies available in simulated robot soccer.
You can read the full research at https://scholar.sun.ac.za/handle/10019.1/125969