


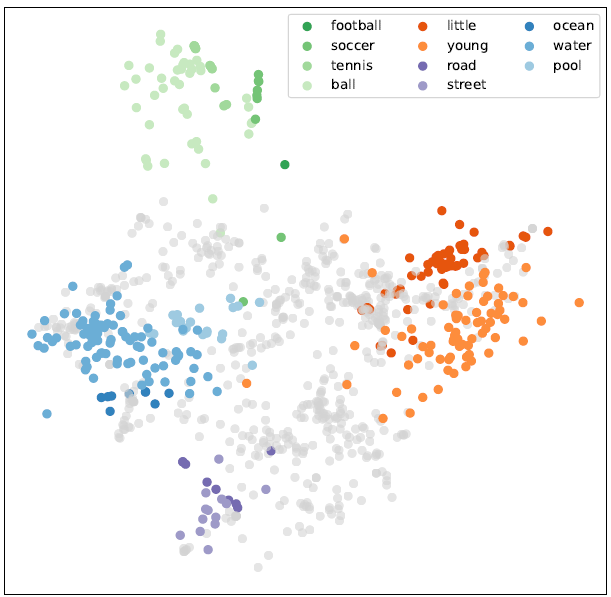
Over the last few years, there have been significant advancements in automatic speech recognition systems. Most state-of-the-art speech applications rely on neural networks with millions or even billions of parameters. However, as network sizes increase, so does the amount of required training data. To put this into perspective, Google Assistant only supports twelve languages, yet there are roughly 7,000 languages spoken throughout the world. However, developing speech applications with neural networks necessitates large amounts of transcribed speech data. The scarcity of labelled speech data poses a restriction on the development of speech applications for only a few well-resourced languages. To tackle this problem, researchers are working towards developing speech models for languages that lack labelled data. In this zero-resource setting, researchers are developing methods that aim to learn meaningful linguistic structures from unlabeled speech alone. Against this background, Dr Christiaan Jacobs, under supervision of Professor Herman Kamper, set out to complete his doctoral research by making very specific contributions to the development of AWE models and their downstream application. We look at this in more detail below. Developing speech applications with neural networks necessitates large amounts of transcribed speech data. The scarcity of labelled speech data poses a restriction on the development of speech applications for only a few well-resourced languages. To tackle this problem, researchers are working towards developing speech models for languages that lack labelled data. In this zero-resource setting, researchers are developing methods that aim to learn meaningful linguistic structures from unlabeled speech alone. Many zero-resource speech applications require the comparison of speech segments with different durations. Acoustic word embeddings (AWEs) are fixed-dimensional representations of variable-duration speech segments. The proximity in vector space should indicate similarity between the original acoustic segments, enabling fast and easy comparison between spoken words. Figure 1: Semantic AWEs capture acoustic similarity among instances of the same word type (represented by the same colour) while also preserving word meaning (reflected in the shade of the same colour). In their thesis, the researcher presents five specific contributions to the development of AWE models and their downstream applications: These contributions aim to advance the field of automatic speech recognition, particularly in addressing data scarcity, improving model performance, and expanding the applicability of AWEs in various downstream tasks. In this study, the researcher introduced the ContrastiveRNN AWE model, optimizing a previously unconsidered distance metric function. The model underwent comparison with existing AWE embedding models, CAE-RNN and SiameseRNN. Both were re-implemented and evaluated against ContrastiveRNN using the same experimental setup as Kamper et al. Results indicate ContrastiveRNN’s superiority in the word discrimination task, with up to a 17.8% increase in average precision in one evaluation language. However, in the supervised multilingual setting, ContrastiveRNN’s performance enhancements over CAE-RNN and SiameseRNN were marginal. A novel training strategy was proposed, extending the multilingual transfer strategy. Following training of a multilingual model, fine-tuning occurred using discovered word-like pairs obtained from an unsupervised term discovery system (UTD) applied to unlabeled speech data in the target language. Results demonstrate ContrastiveRNN’s generally superior adaptation to target languages compared to CAE-RNN and SiameseRNN. The impact of training languages on developing AWE models for specific target languages was further investigated. Experiments on South African languages explored training multilingual AWEs with various language combinations while controlling data quantity. Findings suggest including related languages, even in small quantities, is more beneficial than using unrelated languages, as shown in both intrinsic word discrimination tasks and downstream zero-resource speech tasks. Subsequently, the focus shifted to developing keyword-spotting systems for monitoring hate speech in radio broadcast audio in collaboration with VoxCroft. Existing ASR-based KWS systems requiring labeled training data were compared. Finally, a new form of representation learning of spoken word segments was explored: AWEs reflecting word-type information and word meaning. A pre-trained multilingual AWE model was proposed to assist in this task, showing a significant improvement over existing approaches in an intrinsic word similarity task measuring semantic relatedness. These semantic AWEs were then applied in a downstream semantic speech retrieval task, demonstrating promising results for future applications. To read the full research paper, visit https://scholar.sun.ac.za/items/4c7eca2f-0c01-45cd-b57b-2855505f4050 and download. Addressing Data Scarcity in Speech Applications
Contributions to AWE Development and Downstream Applications
Research Recommendations