


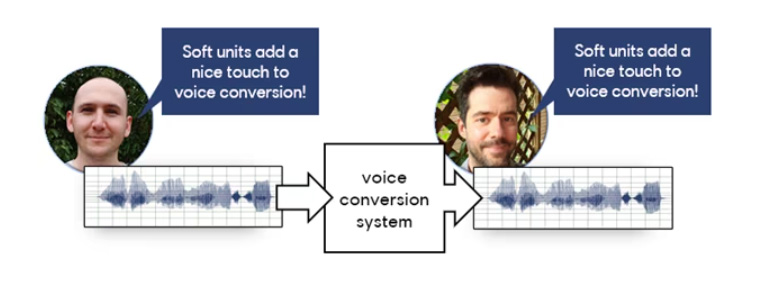
Voice conversion technology transforms spoken words from one individual into the voice of another person. Essentially, it’s like having a machine mimic a recorded sentence in another person’s voice.
This article discusses the representation of speech in a voice conversion model. More specifically, it explains the intuition behind soft speech units that improve upon traditional discrete speech units.
Recently, Professor Herman Kamper of the Department of Electrical and Electronic Engineering at Stellenbosch University and some of his students at the MediaLab have collaborated with Ubisoft, an international gaming company, to explain the intuition behind soft speech units that improve upon traditional discrete speech units.
What is Voice Conversion Technology and How Does it Work?
A voice conversion system captures the phonetic content (what words are spoken) and prosody (how these words are spoken, akin to the sentence’s melody) of a spoken line, while ignoring the speaker’s unique voice characteristics. Once the system encodes this information, it can then recreate the speech in a different voice.
Voice conversion technology is becoming increasingly popular in entertainment due to its unique capabilities. For example, it can recreate the voices of beloved characters when the original actors are no longer available, such as the young Luke Skywalker in The Mandalorian.
It also ensures characters maintain a consistent voice across different languages. Moreover, it offers gamers the exciting opportunity to generate custom content by recording their own dialogue lines and converting them into the voices of their favourite game characters.
Speech Units vs Soft Speech Units
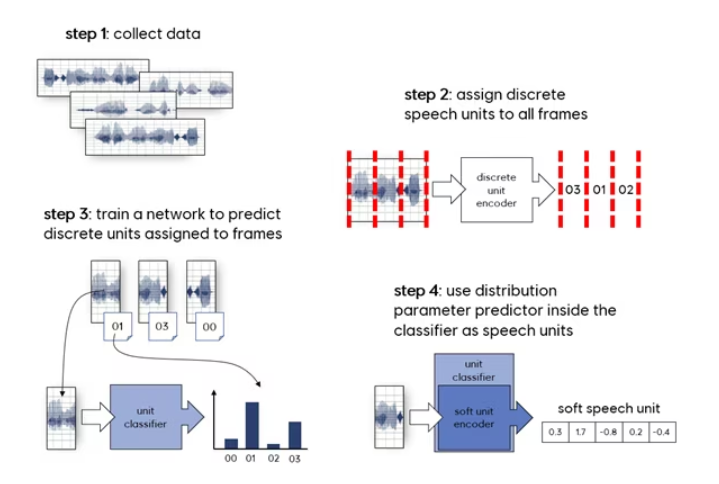
Speech units are symbols that represent typical speech patterns over short time frames. These symbols aren’t defined by humans but are discovered through a data-driven learning process.
The steps to create a dictionary of these speech units involve collecting a large amount of speech data, splitting this data into short frames, encoding them using a feature extractor like MFCC, HuBERT or CPC, and performing clustering on all encoded frames using an algorithm like k-means. The resulting cluster centres become the speech units.
When encoding a speech line, it’s split into short frames and features are extracted and assigned to the nearest cluster centres. As a result, a raw audio signal is translated into a series of cluster IDs, a process that tends to discard speaker-specific information while preserving phonetic and prosodic information.
The traditional method of assigning every piece of speech to a specific cluster can result in phonetic information loss and potential mispronunciations. For example, ambiguous frames in the word “fin” might be incorrectly assigned, resulting in the mispronunciation “thin”.
A new encoding system called soft speech units was proposed to overcome this. It models assignment ambiguity, retaining more content information and correcting mispronunciations. The concept is inspired by soft assignment in computer vision, which has successfully improved classification tasks.
Experiments and Results
Experiments were conducted to compare the effectiveness of traditional discrete speech units with proposed soft speech units in state-of-the-art models. The tests measured intelligibility, speaker similarity, and naturalness using feature extractors like CPC and HuBERT and assessed word and phoneme error rates for speech intelligibility.
Speaker similarity was evaluated using a trained speaker-verification system and naturalness through subjective mean opinion scores. Results indicated that soft speech units increased both intelligibility and naturalness. The HuBERT-based model achieved speech recognition error rates comparable to real speech, albeit with some leakage of speaker identity information. However, these differences were generally imperceptible to humans.
Final Thoughts
Soft speech units were proposed to enhance unsupervised voice conversion. These units strike a balance between discrete and continuous features, effectively representing linguistic content while discarding speaker information. Evaluations confirmed that soft units enhance the intelligibility and naturalness of the speech. Future research will explore the potential of soft speech units in any-to-any voice conversion.
Read the detailed article at https://www.ubisoft.com/en-us/studio/laforge/news/6ZWnQA3LHMBXTBCq33xVFB/soft-speech-units-for-improved-voice-conversion. Soft speech units were introduced in: B. van Niekerk, M.-A. Carbonneau, J. Zaïdi, M. Baas, H. Seuté and H. Kamper, “A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion,” IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, available at https://arxiv.org/abs/2111.02392.